scroll down to view more
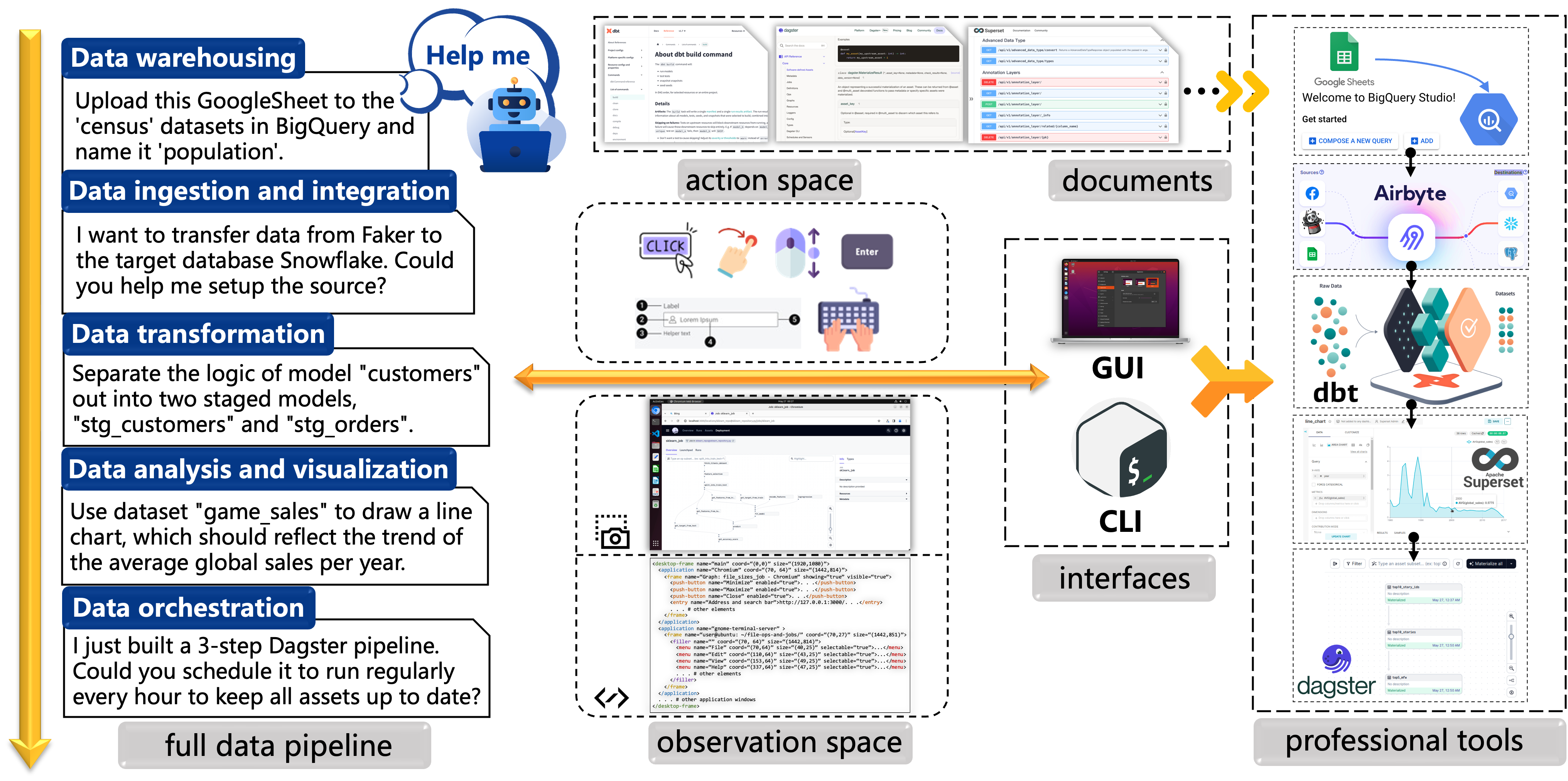
Airbyte and uuid 66936a8e-5cbe-4638-a03a-3ae92eb81e6c) below to showcase:
- 1. .json data format;
- 2. two types of task intructions (abstract and verbose);
- 3. environment setup methods;
- 4. video recording and action trajectory to complete the task;
- 5. task-specific evaluation metric.
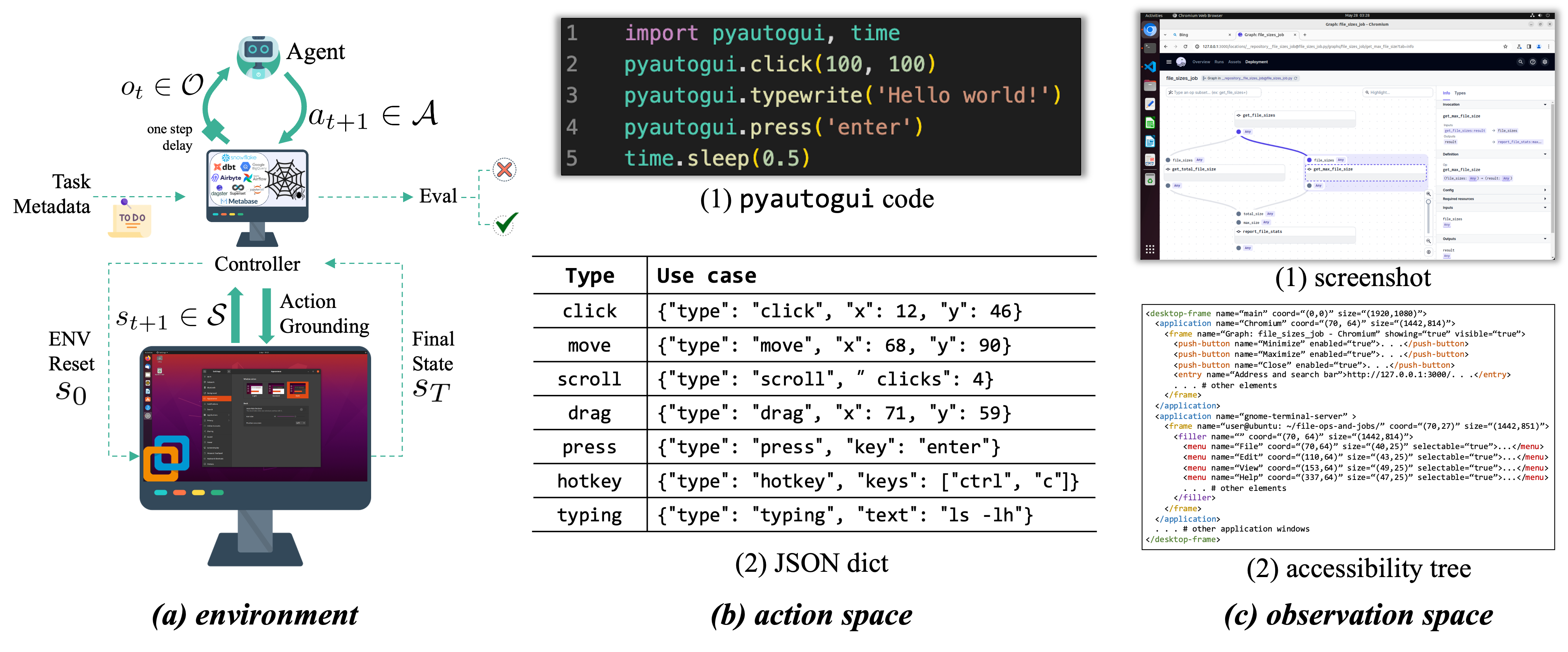
## Action 1
index_80 = (417, 288)
pyautogui.click(index_80)
time.sleep(1)
## Action 2
index_83 = (502, 307)
pyautogui.click(index_83)
time.sleep(1)
## Action 3
index_91 = (883, 404)
pyautogui.click(index_91)
time.sleep(1)
## Action 4
index_102 = (1130, 481)
pyautogui.click(index_102)
time.sleep(1)
## Action 5
index_121 = (1130, 782)
pyautogui.click(index_121)
time.sleep(1)
## Action 6
index_98 = (1130, 430)
pyautogui.click(index_98)
time.sleep(1)
## Action 7
index_105 = (1130, 560)
pyautogui.click(index_105)
time.sleep(1)
## Action 8
index_103 = (1050, 481)
# Clear the current cron expression
pyautogui.click(index_103)
pyautogui.hotkey('ctrl', 'a')
pyautogui.press('backspace')
time.sleep(1)
# Enter the new cron expression
pyautogui.typewrite('0 18 * * *')
time.sleep(1)
## Action 9
index_103 = (1050, 481)
# Clear the current cron expression
pyautogui.click(index_103)
pyautogui.hotkey('ctrl', 'a')
pyautogui.press('backspace')
time.sleep(1)
# Enter the new Quartz cron expression
pyautogui.typewrite('0 0 18 * * ?')
time.sleep(1)
## Action 10
index_134 = (1426, 834)
pyautogui.click(index_134)
time.sleep(1)
## Action 11
DONE
“verbose” means a step-by-step guideline on how to complete the task is included in the instruction.
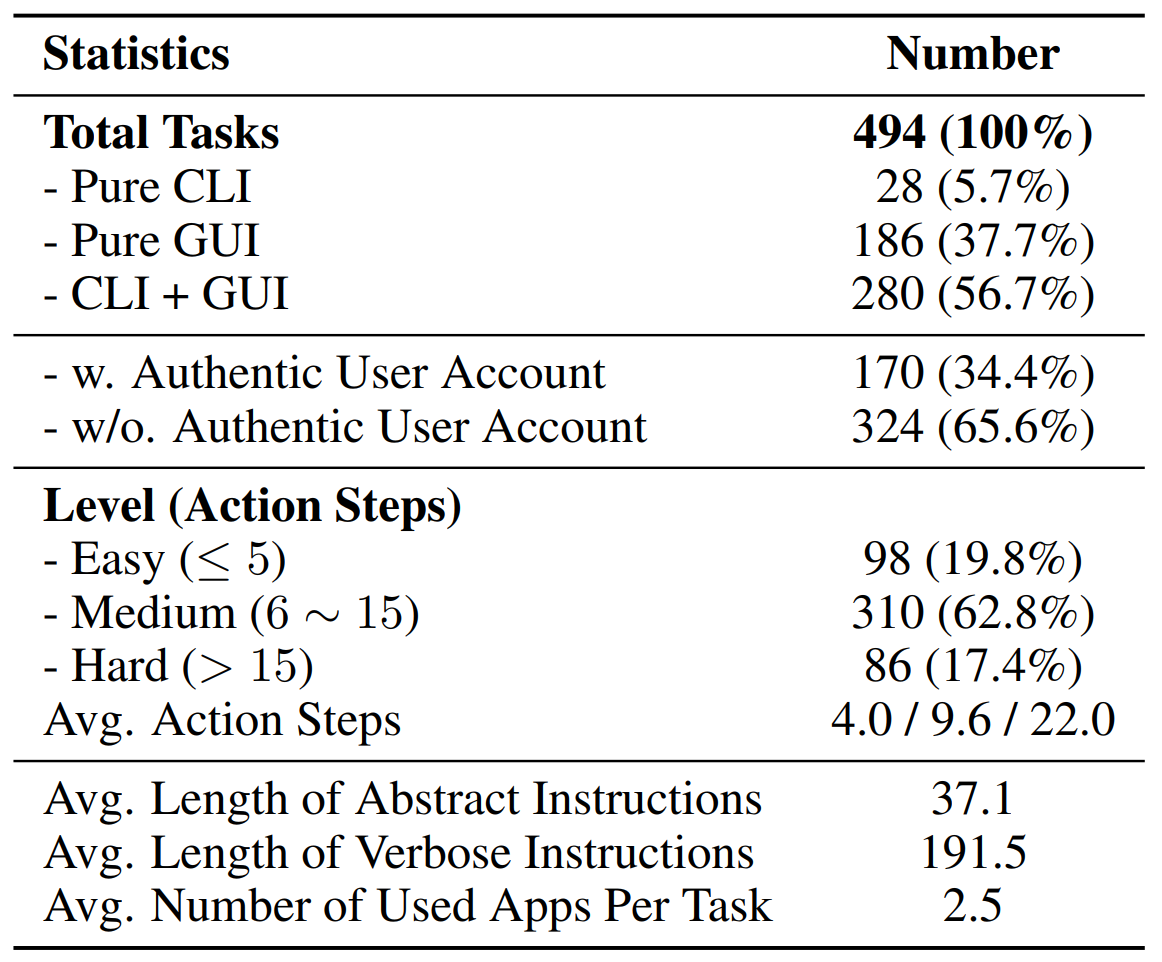
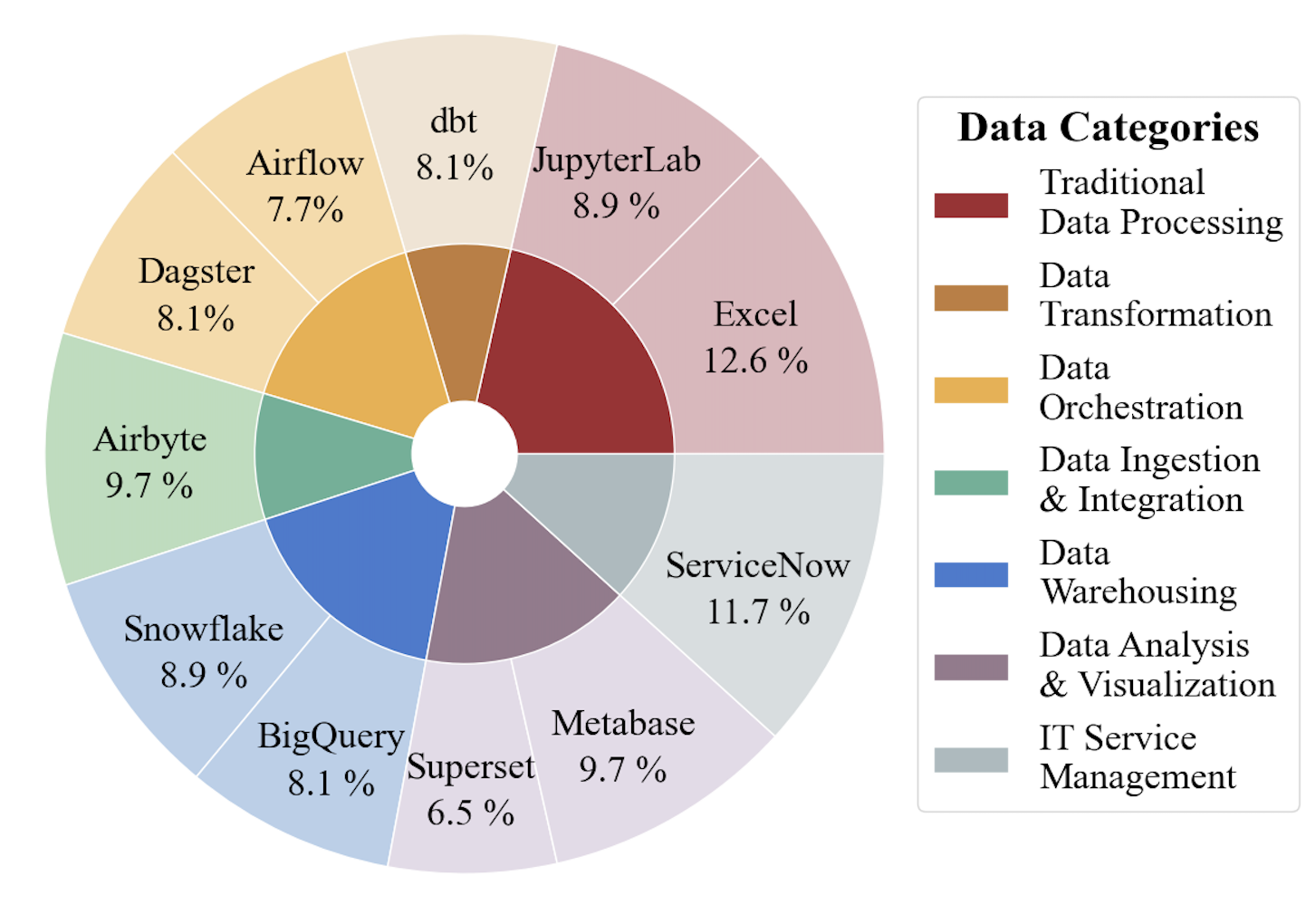
Based on task categories and professional applications to showcase the content intuitively.
| Spider2-V | |
|---|---|
| Field | Data Science &Engineering |
| # Tasks | 494 |
| Exec. Env. ? | ✔️ |
| Enter. Serv.? | ✔️ |
| GUI Support? | ✔️ |
| # Apps/Sites? | 20 |
| # Exec. Eval. Func. | 151 |
| Spider1.0 | DS1000 | Arcade | Intercode | SheetCopilot | MLAgentBench | SWEBench | Mind2Web | WEBLINX | GAIA | WebArena | WorkArena | OSWorld | AitW | AndroidWorld |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text-to-SQL | Data Science | Data Science | Data Science | Sheet Coding | Machine Learning | Software Engineering | Web | Web | Web | Web | Web | Computer Control | Android | Android |
| 1034 | 1000 | 1082 | 1350 | 221 | 13 | 2294 | 2000 | 2337 | 466 | 812 | 29 | 369 | 30k | 116 |
| ❌ | ❌ | ❌ | ✔️ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ✔️ |
| ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| 1 | 1 | 1 | 3 | 1 | 4 | 12 | 137 | 155 | n/a | 5 | 1 | 9 | 357 | 20 |
| 0 | 0 | 0 | 3 | 0 | 13 | 1 | 0 | 0 | 0 | 5 | 7 | 134 | 0 | 6 |
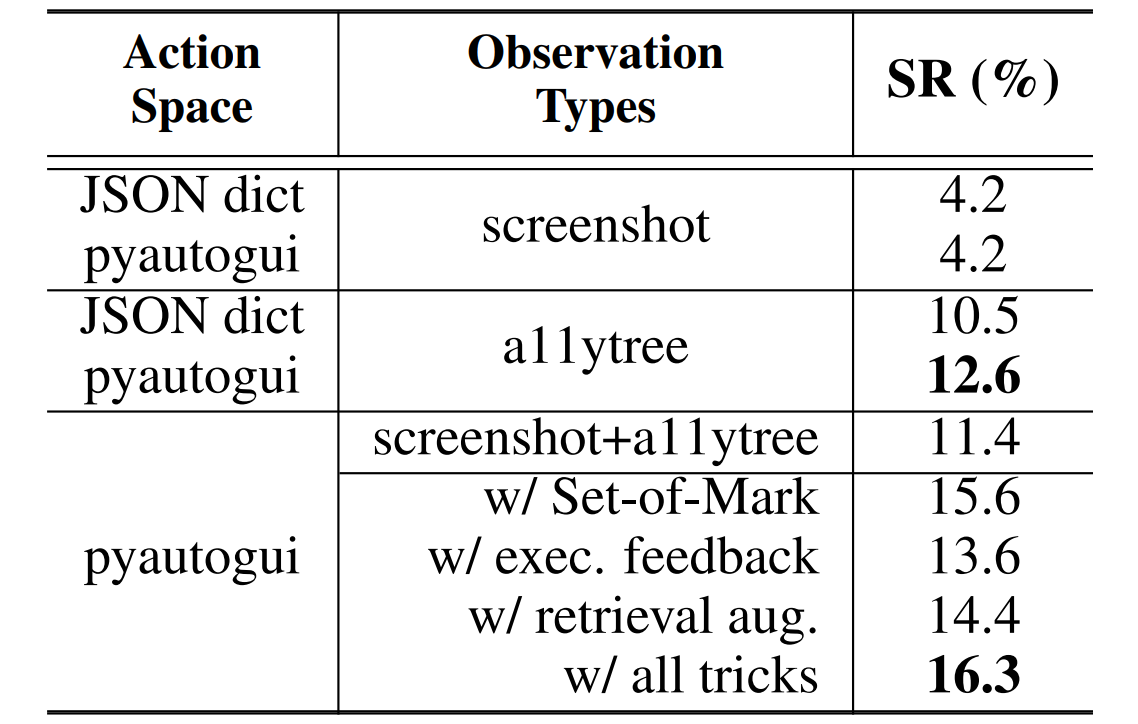
| Rank | Model | Details | Score |
|---|---|---|---|
|
1 Jun 3, 2024 |
GPT-4V (1106)
OpenAI OpenAI, '23 |
SoM + EF + RAG t=1.0, top-p=0.9 len = 128k |
14.0 |
|
2 Jun 2, 2024 |
GPT-4o (0513)
OpenAI OpenAI, '24 |
SoM + EF + RAG t=1.0, top-p=0.9 len = 128k |
13.8 |
|
3 Jun 5, 2024 |
Gemini-Pro-1.5
|
SoM + EF + RAG t=1.0, top-p=0.9 len = 128k |
9.1 |
|
4 June 6, 2024 |
Claude-3-Opus
AnthropicAI Anthropic, '24 |
SoM + EF + RAG t=1.0, top-p=0.9 len = 200k |
8.1 |
|
5 June 6, 2024 |
Llama-3-70B
Meta Meta Llama, Meta, '24 |
a11ytree + EF + RAG t=1.0, top-p=0.9 len = 32k |
2.0 |
|
6 June 6, 2024 |
Mixtral-8x7B
MistralAI Jiang et al., '24 |
a11ytree + EF + RAG t=1.0, top-p=0.9 len = 32k |
0.8 |
|
7 June 6, 2024 |
Qwen-Max
Qwen Qwen Team, '24 |
a11ytree + EF + RAG t=1.0, top-p=0.9 len = 32k |
0.6 |
We thank Yiheng Xu, Hongjin Su, Xiaochuan Li, and Toh Jing Hua for their helpful assistance and feedback on this work.
The Github repository, virtual machine snapshots, crawled documents can be downloaded from:
- Github repository: Spider2-V (including environment and task examples)
- VM snapshots: ubuntu-arm.zip or ubuntu-x86.zip
- Crawled documents docs.zip
The username and password for the virtual machines are as follows:
- Username: user
- Password: password
See Account Guideline.
See Proxy Guideline.
You can put forward an issue on the Github repository or email to ruishengcao@gmail.com , tyu@cs.hku.hk .
@article{2024-spider2v,
title={Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?},
author={Ruisheng Cao and Fangyu Lei and Haoyuan Wu and Jixuan Chen and Yeqiao Fu and Hongcheng Gao and Xinzhuang Xiong and Hanchong Zhang and Yuchen Mao and Wenjing Hu and Tianbao Xie and Hongshen Xu and Danyang Zhang and Sida Wang and Ruoxi Sun and Pengcheng Yin and Caiming Xiong and Ansong Ni and Qian Liu and Victor Zhong and Lu Chen and Kai Yu and Tao Yu},
year={2024},
journal={CoRR},
volume={abs/2407.10956},
eprint={2407.10956},
eprinttype={arXiv},
url={https://arxiv.org/abs/2407.10956}
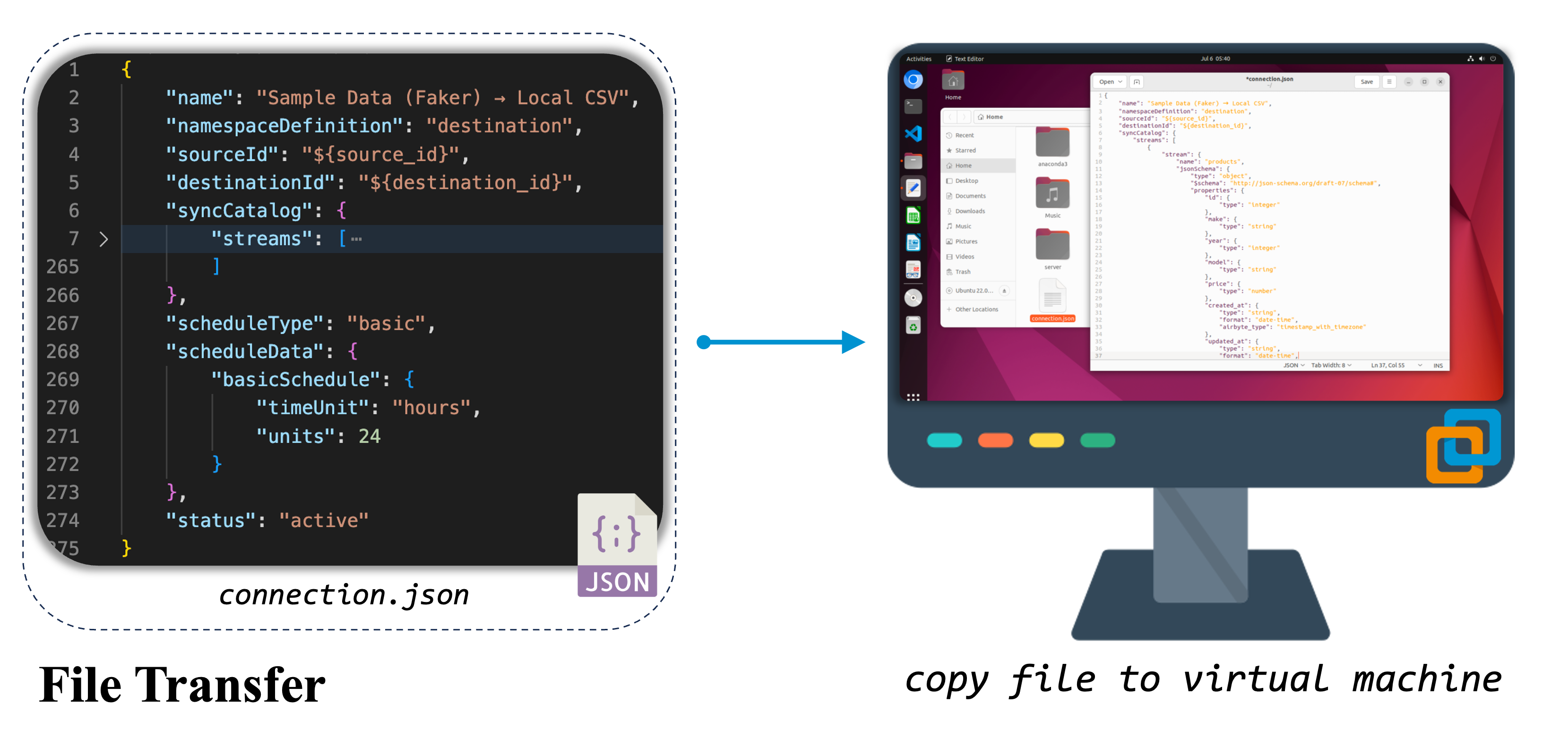
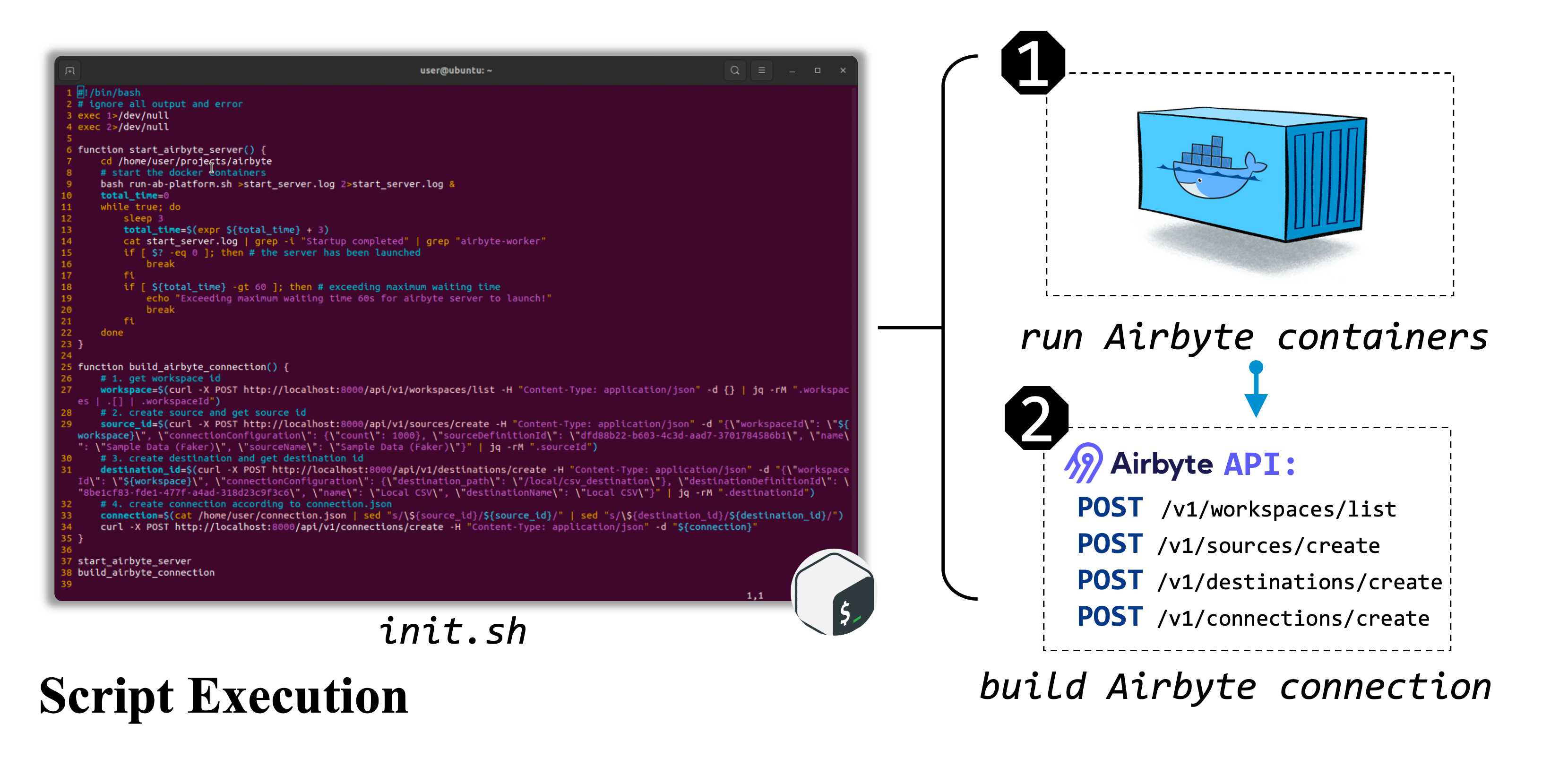
}
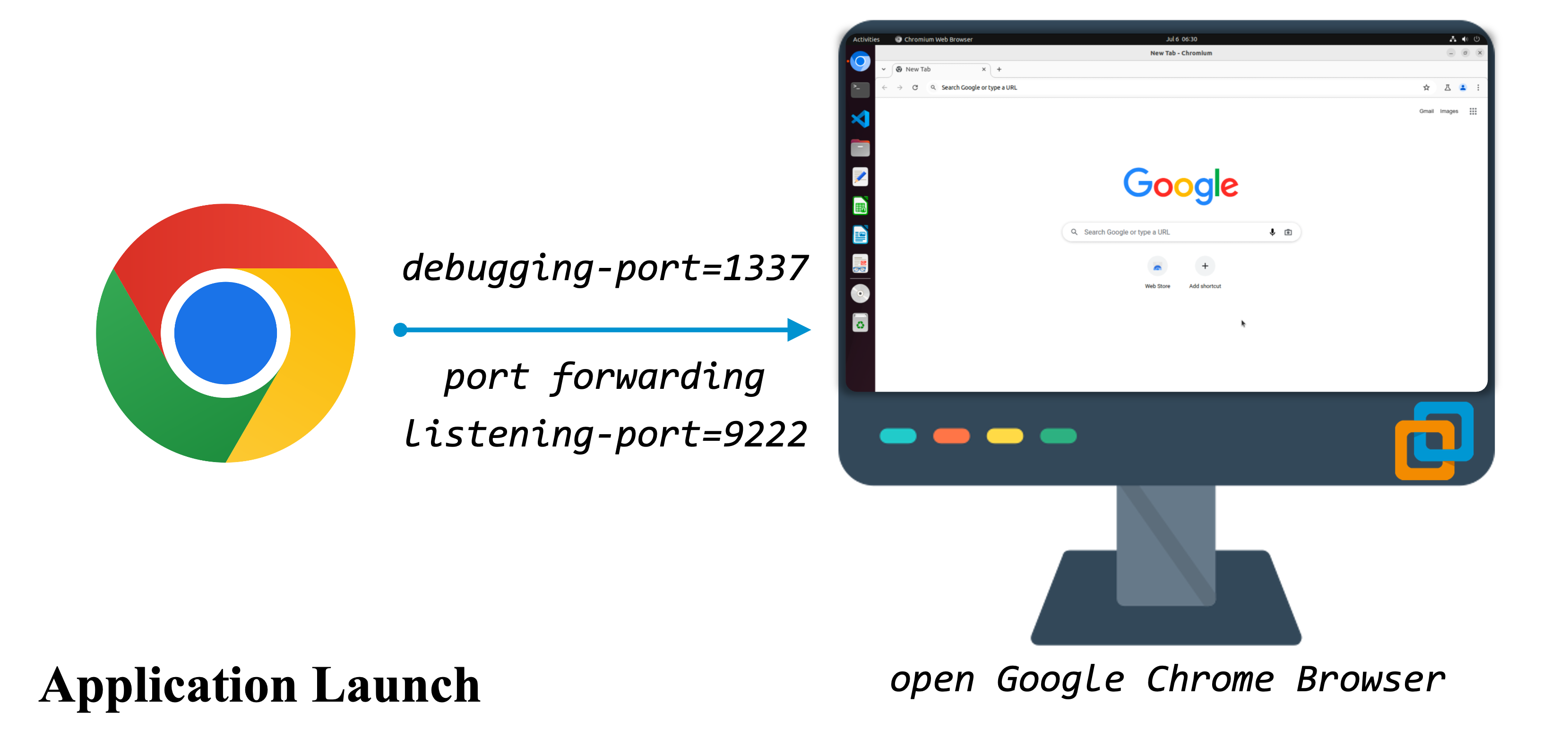
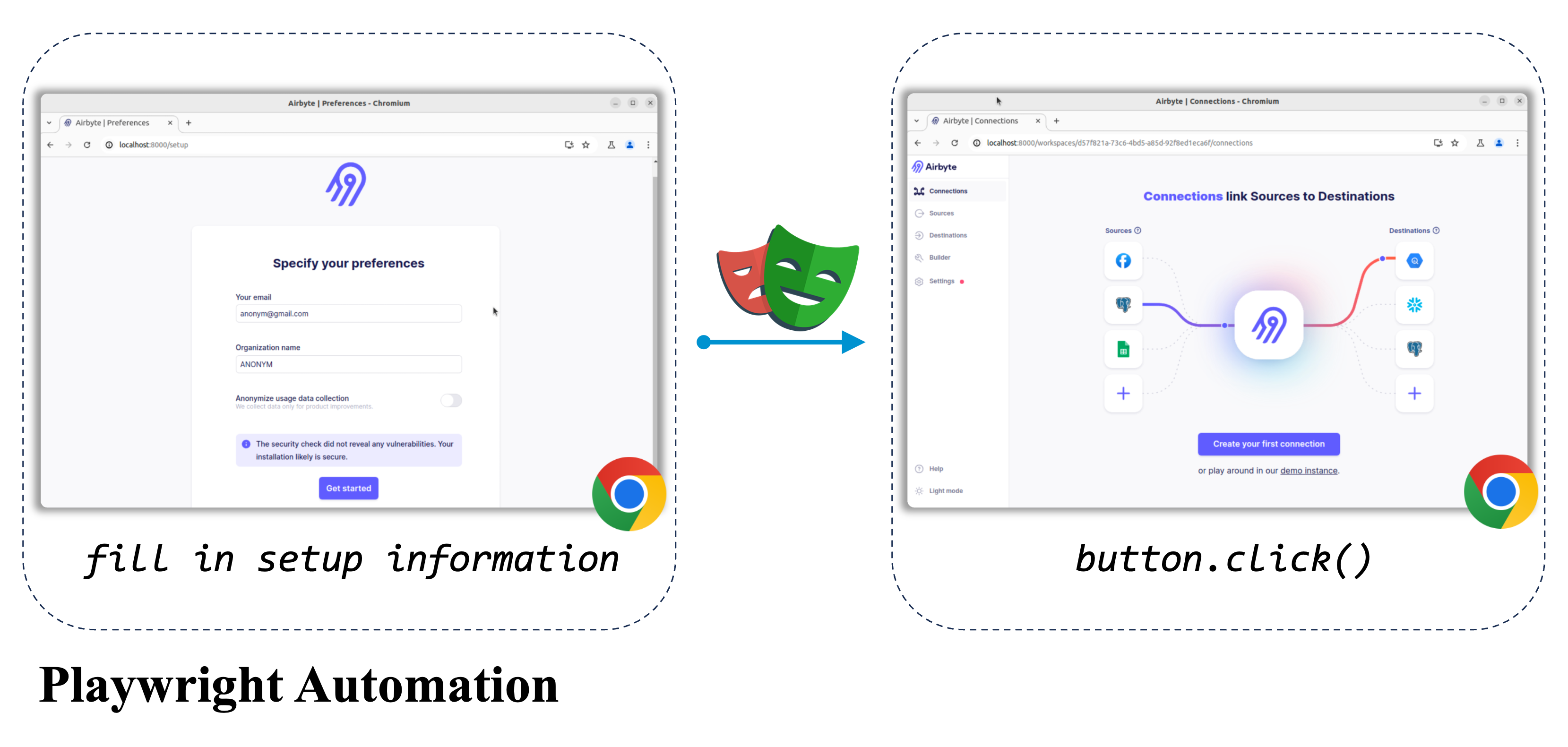
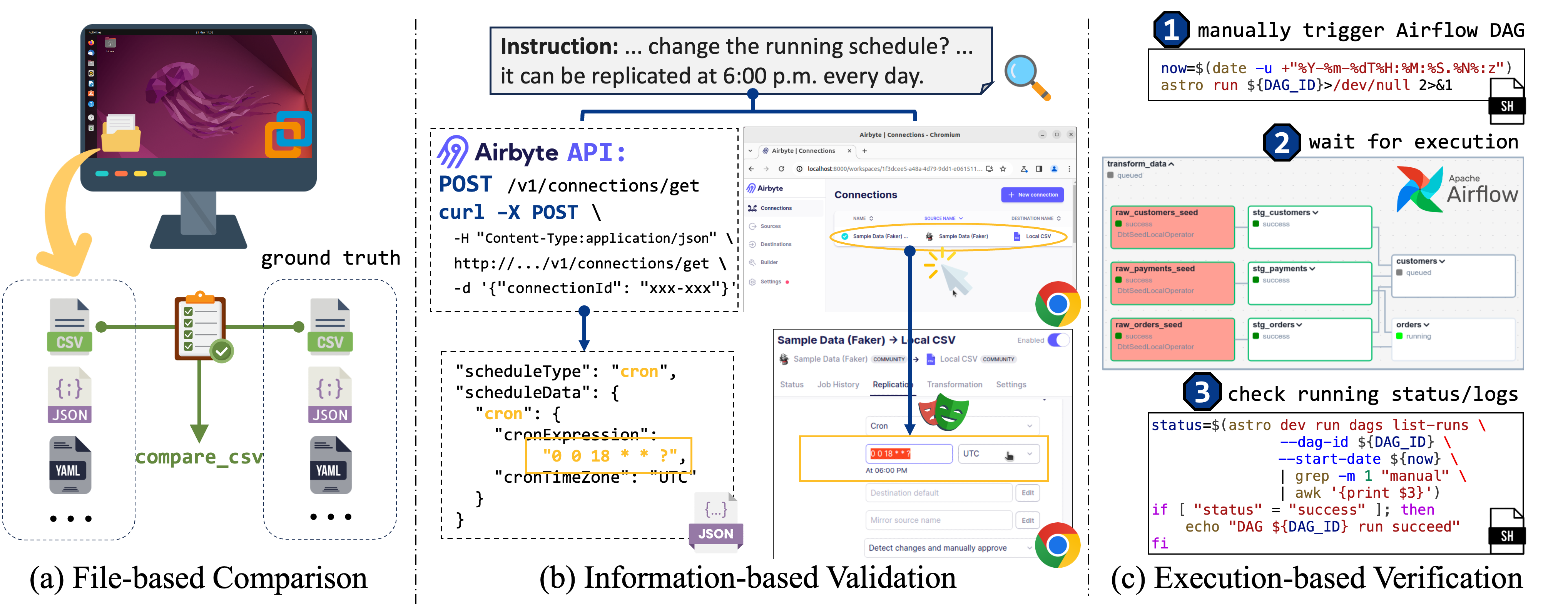 In the current task, we adopt the information-based metric to check whether the schedule is correctly altered to
In the current task, we adopt the information-based metric to check whether the schedule is correctly altered to